
Google Cloud Platform (GCP) is one of the most popular cloud providers in the IT industry, which allows developers, cloud administrators, and other enterprise IT professionals to work through the public Internet or a dedicated network connection to build, test and deploy applications in a real-time environment.
In 2021, Google announced the launch of a new cloud platform for machine learning (ML) — Vertex AI.
The main advantages of Vertex AI are scalability and the ability to integrate with Google Cloud. This platform combines all cloud tools for data processing and model training. Therefore, teams have got the opportunity to transfer all ML processes to Vertex AI.
Google cloud developers have also provided the opportunity to use the platform in custom ways, so you can embed your code into the platform and use only the Vertex AI tools needed for current tasks.
In 2021, Google announced the launch of a new cloud platform for machine learning (ML) — Vertex AI.
The main advantages of Vertex AI are scalability and the ability to integrate with Google Cloud. This platform combines all cloud tools for data processing and model training. Therefore, teams have got the opportunity to transfer all ML processes to Vertex AI.
Google cloud developers have also provided the opportunity to use the platform in custom ways, so you can embed your code into the platform and use only the Vertex AI tools needed for current tasks.

GCP is an ever-evolving platform that improves and launches new products and solutions for cloud development and deployment.
In this regard, we decided to “dive” into the cloud ML development on the Google platform, explore its capabilities, compare tools, calculate the necessary resources and highlight the pros and cons of its latest products.
Our project is an experimental study aimed at developing a ready-to-use fully deployed recommendation computer vision (CV) system for an online store based on “Fashion product images” kaggle dataset.
This article consists of several parts describing our experience inbuilding a visual similarity recommendation system using three approaches:
The expected result of each method is a ready-made Deep Learning (DL) product deployed in the cloud, which can be used by e-commerce sites to offer products to their users and provide additional information to help customers decide which products to purchase.
In this version of the projects, we solve only the basic academic problem of recommendation selection. However, in further steps, this recommendation system will also consider user clicks on the products shown in the carousel of similar goods.
In conclusion, we compare the methods used and give our feedback on innovative tools provided by the Google Cloud Platform.
To better understand how the system will work, we provide the following diagram illustrating the architecture of the project:
In this regard, we decided to “dive” into the cloud ML development on the Google platform, explore its capabilities, compare tools, calculate the necessary resources and highlight the pros and cons of its latest products.
Our project is an experimental study aimed at developing a ready-to-use fully deployed recommendation computer vision (CV) system for an online store based on “Fashion product images” kaggle dataset.
This article consists of several parts describing our experience inbuilding a visual similarity recommendation system using three approaches:
- without any Google solutions for ML development;
- partially using GCP: automatic data labeling, the model creation and training using the Vertex AI Auto ML and Vertex AI Datasets;
- through the full use of GCP Vertex AI tools in all ML tasks of the project.
The expected result of each method is a ready-made Deep Learning (DL) product deployed in the cloud, which can be used by e-commerce sites to offer products to their users and provide additional information to help customers decide which products to purchase.
In this version of the projects, we solve only the basic academic problem of recommendation selection. However, in further steps, this recommendation system will also consider user clicks on the products shown in the carousel of similar goods.
In conclusion, we compare the methods used and give our feedback on innovative tools provided by the Google Cloud Platform.
To better understand how the system will work, we provide the following diagram illustrating the architecture of the project:
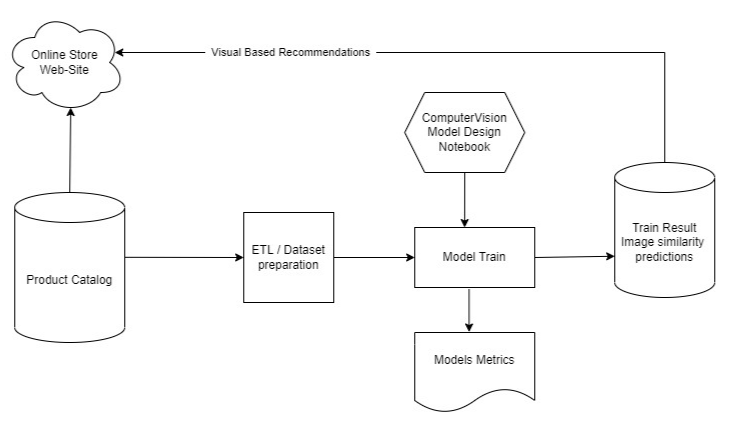
To realize the idea, we designed a prototype of an online clothing store and filled out its product catalog based on the kaggle open dataset "Fashion Product Images Dataset", which contains 8297 images. Our online store is the simple REST API in Python using the Flask framework.
*DISCLAIMER: The system presented in this article is a RnD (Research and Development) project aimed at studying and researching innovative GCP tools. Our product is not a ready-made commercial offer. The key conclusions from this material should be the development workflow, familiarity with the technology stack and getting the first experience to create a visual search system using ML.
Tech-stack: Python, Flask, Docker, Git, Webhooks, Terraform, Tensorflow, Keras, math, faiss, Scikit-learn, numpy, pandas, openCV, PIL, Google Cloud Platform.
*DISCLAIMER: The system presented in this article is a RnD (Research and Development) project aimed at studying and researching innovative GCP tools. Our product is not a ready-made commercial offer. The key conclusions from this material should be the development workflow, familiarity with the technology stack and getting the first experience to create a visual search system using ML.
Tech-stack: Python, Flask, Docker, Git, Webhooks, Terraform, Tensorflow, Keras, math, faiss, Scikit-learn, numpy, pandas, openCV, PIL, Google Cloud Platform.
Building Recommendation System using pre-trained model VGG-19
The main goal of this section is to build our CV system using a pre-trained model that already has weights and there is no need to change hyperparameters.
Instead, we only need to prepare necessary data, to consider how to process model predictions and to solve issues related to data storage structure and its submission to the store interface.
As already mentioned, the deployment tasks will be solved using Google Cloud technologies. In this part, we will consider the tasks of ML development.
The workflow can be divided into following basic steps:
Below, there are key tools and technologies that we have used in this section:
🡺 Dataset – Fashion Product Images Dataset [kaggle];
🡺 Pre- and post-processing of data – custom library ‘deep_image_search_tools’;
🡺 Model – pre-trained VGG19 [PyTorch];
🡺 Storage Tools:
Let's look at this in more detail.
Model
VGG-19 is a deep convolutional neural network (CNN) architecture that was developed by the Visual Geometry Group (VGG) at the University of Oxford. It is part of the VGG family of models, which includes variations with different numbers of layers. VGG-19 is notable for its depth, consisting of 19 layers (hence the name) with learnable parameters.
Based on CNN's structure, the VGG-19 has two fundamental concepts:
1) Convolution
This concept preserves the relationship between pixels by studying the features of the image using small squares of input data. Convolution is a mathematical operation that allows the merging of two sets of information. In case of CNN, convolution is applied to the input data to filter the information and produce a feature map.
Instead, we only need to prepare necessary data, to consider how to process model predictions and to solve issues related to data storage structure and its submission to the store interface.
As already mentioned, the deployment tasks will be solved using Google Cloud technologies. In this part, we will consider the tasks of ML development.
The workflow can be divided into following basic steps:
- Pre-processing the data.
- Running a pre-trained machine learning model on a local system for getting predictions.
- Post-processing of the model results.
- Wrapping the inference logic into a flask application.
- Using docker to containerize the flask application.
- Hosting the docker image on Google Cloud Artifact Registry
- Running docker image using Google Cloud Composer with Google Cloud Compute Engine and consuming the web-service.
Below, there are key tools and technologies that we have used in this section:
🡺 Dataset – Fashion Product Images Dataset [kaggle];
🡺 Pre- and post-processing of data – custom library ‘deep_image_search_tools’;
🡺 Model – pre-trained VGG19 [PyTorch];
🡺 Storage Tools:
- Google Cloud Storage – for images,
- Google Cloud Firestore – for metadata,
- Google Cloud Artifact Registry – for docker images;
Let's look at this in more detail.
Model
VGG-19 is a deep convolutional neural network (CNN) architecture that was developed by the Visual Geometry Group (VGG) at the University of Oxford. It is part of the VGG family of models, which includes variations with different numbers of layers. VGG-19 is notable for its depth, consisting of 19 layers (hence the name) with learnable parameters.
Based on CNN's structure, the VGG-19 has two fundamental concepts:
1) Convolution
This concept preserves the relationship between pixels by studying the features of the image using small squares of input data. Convolution is a mathematical operation that allows the merging of two sets of information. In case of CNN, convolution is applied to the input data to filter the information and produce a feature map.

This filter is also called a kernel, or feature detector, and its dimensions can be, for example, 3x3. To perform convolution, the kernel goes over the input image, doing matrix multiplication element by element. The result for each receptive field (the area where convolution takes place) is written down in the feature map.

We continue sliding the filter until the feature map is completed.
In a convolutional layer there are multiple filters, and each of them generates a filter map. Therefore, the layer output will be presented as a set of filter maps, stacked on top of each other.
2) Subsampling operation (pooling, max pooling)
A pooling layer receives the result from a convolutional layer and compresses it. The filter of a pooling layer is always smaller than a feature map. Usually, it takes a 2x2 square (patch) and compresses it into one value.
A 2x2 filter would reduce the number of pixels in each feature map to one quarter the size.
Multiple different functions can be used for pooling. These are the most frequent ones:
● Maximum Pooling. It calculates the maximum value for each patch of the feature map.
● Average pooling. It calculates the average value for each patch on the feature map.
After using the pooling layer, you get pooled feature maps that are a summarized version of the features detected in the input.
Let’s take a brief look at the VGG19 architecture.
In a convolutional layer there are multiple filters, and each of them generates a filter map. Therefore, the layer output will be presented as a set of filter maps, stacked on top of each other.
2) Subsampling operation (pooling, max pooling)
A pooling layer receives the result from a convolutional layer and compresses it. The filter of a pooling layer is always smaller than a feature map. Usually, it takes a 2x2 square (patch) and compresses it into one value.
A 2x2 filter would reduce the number of pixels in each feature map to one quarter the size.
Multiple different functions can be used for pooling. These are the most frequent ones:
● Maximum Pooling. It calculates the maximum value for each patch of the feature map.
● Average pooling. It calculates the average value for each patch on the feature map.
After using the pooling layer, you get pooled feature maps that are a summarized version of the features detected in the input.
Let’s take a brief look at the VGG19 architecture.

● Input: The VGG-19 takes in an image input size of 224×224.
● Convolutional Layers: VGG’s convolutional layers leverage a minimal receptive field, i.e., 3×3, the smallest possible size that still captures up/down and left/right. This is followed by a ReLU activation function. ReLU stands for rectified linear unit activation function - a piecewise linear function that will output the input if positive, otherwise, the output is zero. Stride is fixed at 1 pixel to keep the spatial resolution preserved after convolution
● Fully-Connected Layers: The VGG19 has 3 fully connected layers. The first 2 layers have 4096 nodes each, and the third one has 1000 nodes, which is the total number of classes the imagenet dataset has.
So, for our study, we imported a pre-trained VGG-19 model using the PyTorch library.
We also have written our own custom library to provide all the necessary image preprocessing operations.
Storage
Where did we decide to store the whole dataset? In the Google Cloud Storage bucket.
Information about the products, including the ID, type, color and other details of each product, was posted in the Google Cloud Firestore, in the format of the documents collection for each of the 8297 images:
● Convolutional Layers: VGG’s convolutional layers leverage a minimal receptive field, i.e., 3×3, the smallest possible size that still captures up/down and left/right. This is followed by a ReLU activation function. ReLU stands for rectified linear unit activation function - a piecewise linear function that will output the input if positive, otherwise, the output is zero. Stride is fixed at 1 pixel to keep the spatial resolution preserved after convolution
● Fully-Connected Layers: The VGG19 has 3 fully connected layers. The first 2 layers have 4096 nodes each, and the third one has 1000 nodes, which is the total number of classes the imagenet dataset has.
So, for our study, we imported a pre-trained VGG-19 model using the PyTorch library.
We also have written our own custom library to provide all the necessary image preprocessing operations.
Storage
Where did we decide to store the whole dataset? In the Google Cloud Storage bucket.
Information about the products, including the ID, type, color and other details of each product, was posted in the Google Cloud Firestore, in the format of the documents collection for each of the 8297 images:
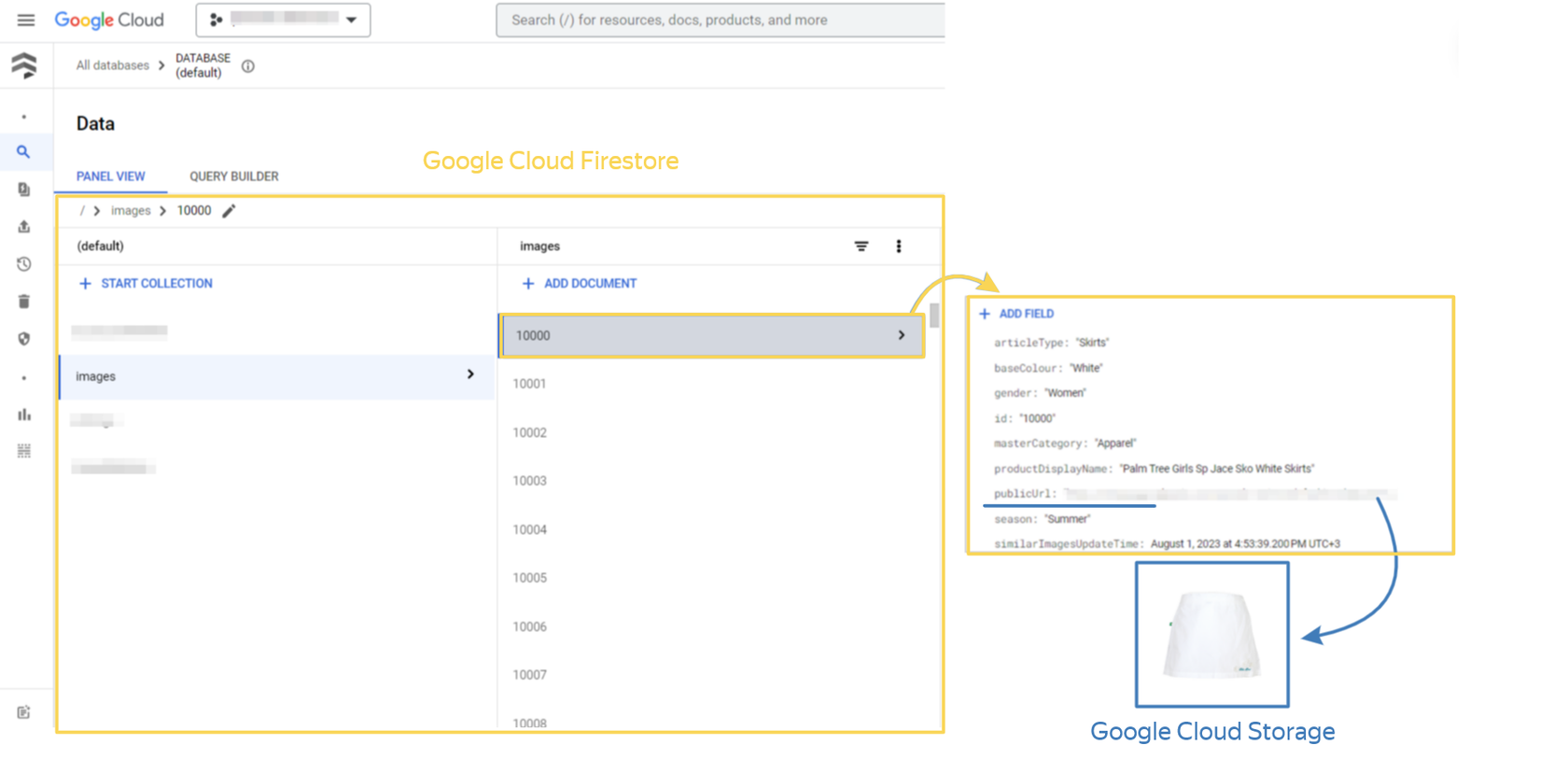
There are also fields called ‘publicUrl’ that contain links to images in the Cloud Storage.
As a result, the interface of our online store successfully received all the necessary information for product cards, including the corresponding images for the clothing catalog.
The prototype of the store's interface is shown below:
As a result, the interface of our online store successfully received all the necessary information for product cards, including the corresponding images for the clothing catalog.
The prototype of the store's interface is shown below:

Matching Similarities
Once the information and images in the storage were placed, we set up the main mechanism – import a pre-trained VGG-19 model with its own weights and get forecasts.
To do this, we initialize the search configuration mechanism – the tool of our custom ‘deep_image_search_tools’ library and then run an indexing engine that extracts objects from the dataset and indexes them. If the metadata and features are already present, the method prompts the user to confirm whether to re-extract the features or not. The method also loads the metadata and feature vectors from the saved pickle file.
Then we load indexes into the imported model to get sets of feature vectors of the images.
After that we run a special method in our custom library called ‘get_similars’ which involves calculating the cosine distance between feature vectors. The most similar images are the images having the smallest cosine distance value compared to the input image. The operation is repeated for each product in our catalog.
To compute the cosine distance between samples in X and Y we use the Scikit-learn library tool:
Once the information and images in the storage were placed, we set up the main mechanism – import a pre-trained VGG-19 model with its own weights and get forecasts.
To do this, we initialize the search configuration mechanism – the tool of our custom ‘deep_image_search_tools’ library and then run an indexing engine that extracts objects from the dataset and indexes them. If the metadata and features are already present, the method prompts the user to confirm whether to re-extract the features or not. The method also loads the metadata and feature vectors from the saved pickle file.
Then we load indexes into the imported model to get sets of feature vectors of the images.
After that we run a special method in our custom library called ‘get_similars’ which involves calculating the cosine distance between feature vectors. The most similar images are the images having the smallest cosine distance value compared to the input image. The operation is repeated for each product in our catalog.
To compute the cosine distance between samples in X and Y we use the Scikit-learn library tool:
sklearn.metrics.pairwise.cosine_distances(X, Y=None)
***The cosine distance similarity metric is a mathematical measure that calculates the angle between two vectors in a multi-dimensional space. It is commonly used in machine learning and data analysis, particularly in text analysis, where each document is represented as a vector of word frequencies. The cosine distance metric is named after the cosine function, which is used to calculate the angle between the vectors.
To demonstrate this, we present the model search results for some products:
To demonstrate this, we present the model search results for some products:

By implementing this approach, we can generate sets of similar images for the entire dataset. The next step is to load these sets onto our cloud storage.
After that, we take several actions:
The figure below represents the final structure of how the information about similar images is stored:
After that, we take several actions:
- Create sub-collections called ‘similar_images’ in our Google Cloud Firestore image collection for each item in the dataset;
- Provide loading of selected images and information about them as separate documents in the ‘similar_images’ collection for each element of the source dataset;
- Calculate and add the percentage of similarity of the selected image to each document;
- Display recommendations on similar elements in each product card on the store's front-end page.
The figure below represents the final structure of how the information about similar images is stored:

The next figure shows the recommendations that appeared in the interface of the online store:

Additionally, to illustrate how described system works, we provide a simple schema below:

Up to this point, the entire process of learning, extracting and comparing vectors took place on a local machine. In the next part of this article we will show you how to deploy our recommendation system for visual similarity search on Google Cloud Platform.
Results
As a result, we build a ready-to-use fully deployed recommendation system of visually similar products for an online clothing store.
Here are the main points of the technology stack splitted by stages of development:
As a result, we build a ready-to-use fully deployed recommendation system of visually similar products for an online clothing store.
Here are the main points of the technology stack splitted by stages of development:

Second, the table below represents the main metrics of Part 2.1:

*DISCLAIMER: These values are high-level evaluations. They are based only on our calculations and experience. The cost of using GCP tools should be calculated individually, based on a variety of factors, such as the model and capacity of the hardware etc. You can find the current version of the cost of Google components on the official website.
As you can see, despite our incomplete development cycle and experience in working with only 10% of the entire data set, the pipeline time and platform costs turned out to be quite significant. Using the GCP tools, you should always be aware of their prices and calculation policy.
!NOTE: Be careful and always check the up-to-date information about the cost of using GCP tools in the official documentation to avoid the situation described in the following article: We Burnt $72K testing Firebase + Cloud Run and almost went Bankrupt [Part 1]
This way of ML development is suitable for those who want to solve classification or object detection tasks in a simple way, without deep involvement in model setup, and who want to get a model with the best learning outcomes, ready for use in real time. But it also means they have to be willing to pay for such demands.
Let's take a look at the pros, cons and pitfalls that we have understood.
PROS of using Vertex AI: AutoML for Computer Vision tasks:
CONS of using Vertex AI: AutoML for Computer Vision tasks:
PITFALLS of using Vertex AI: AutoML for Computer Vision tasks:
In summary, Vertex AI AutoML offers efficiency and accessibility for ML tasks but may have limitations in terms of customization, interpretability, data quality requirements and the cost of using tools.
As you can see, despite our incomplete development cycle and experience in working with only 10% of the entire data set, the pipeline time and platform costs turned out to be quite significant. Using the GCP tools, you should always be aware of their prices and calculation policy.
!NOTE: Be careful and always check the up-to-date information about the cost of using GCP tools in the official documentation to avoid the situation described in the following article: We Burnt $72K testing Firebase + Cloud Run and almost went Bankrupt [Part 1]
This way of ML development is suitable for those who want to solve classification or object detection tasks in a simple way, without deep involvement in model setup, and who want to get a model with the best learning outcomes, ready for use in real time. But it also means they have to be willing to pay for such demands.
Let's take a look at the pros, cons and pitfalls that we have understood.
PROS of using Vertex AI: AutoML for Computer Vision tasks:
- Efficiency in Model Development: Vertex AI AutoML simplifies the process of developing CV models by automating tasks such as architecture selection, hyperparameter tuning, and data preprocessing. This can significantly reduce the time and effort required to build and deploy CV models.
- User-Friendly Interface: It offers a user-friendly interface that doesn't require extensive machine learning expertise, making it accessible to a broader range of users, including those with limited CV experience.
- Scalability: It can handle large datasets and scale to accommodate the data needs of enterprise-level CV projects, making it suitable for organizations with growing demands.
- Cloud Integration: Vertex AI AutoML seamlessly integrates with Google Cloud services, providing easy access to cloud-based resources, data storage, and computing power for CV tasks.
CONS of using Vertex AI: AutoML for Computer Vision tasks:
- Limited Customization: Users may have less control over the model architectures and fine-tuning options compared to custom CV models developed by experts. This limitation can be a drawback for advanced users who require highly customized models.
- Cost Considerations: The use of Vertex AI AutoML may incur costs, which can become significant for large-scale CV projects. Organizations should carefully assess the cost implications and budget accordingly.
- Data Quality Requirements: The performance of CV models generated by AutoML heavily depends on the quality and quantity of the input data. Noisy or biased data can lead to suboptimal results, necessitating data preprocessing and cleaning.
- Interpretability Challenges: AutoML-generated CV models may lack transparency and interpretability, making it challenging to understand why certain predictions are made. This can be a concern in applications requiring model accountability and explanations.
PITFALLS of using Vertex AI: AutoML for Computer Vision tasks:
- Model Evaluation Expertise: While AutoML handles many aspects of model training, users should possess the expertise to evaluate and validate CV models effectively. Relying solely on automated evaluation metrics may lead to subpar model performance.
- Pricing policy: Users who are not aware of the cost structure or have studied the vague pricing policy of using tools may inadvertently incur unforeseen expenses and may continue to use tools without thinking about the financial consequences. This may result in bills being significantly higher than expected. To avoid this, users should take the time to understand the cost structure of the tools they use.
In summary, Vertex AI AutoML offers efficiency and accessibility for ML tasks but may have limitations in terms of customization, interpretability, data quality requirements and the cost of using tools.
Building Recommendation System using Google Cloud Vertex AI: Custom ML
Vertex AI: Custom ML is a machine learning service offered by Google Cloud's Vertex AI platform. It allows developers to create and train their own custom machine learning models using their own data, algorithms, and hyperparameters. This service provides a flexible and scalable solution for businesses looking to build and deploy custom machine learning models to solve complex problems in various industries. With Vertex AI: Custom ML, developers have access to a wide range of tools and resources to help them build, train, and deploy their models quickly and efficiently.
Here are the stages that we went through when building our recommendation CV system:
Below we present key information about the tools and technologies we used:
🡺 Dataset – Fashion Product Images Dataset [kaggle];
🡺 Pre- and post-processing of data – using custom ML tools and libraries;
🡺 Model – Custom Autoencoder model (Tensorflow, Keras);
🡺 Google Cloud Platform Tools for ML Development:
▪ Vertex AI: Workbench – for developing;
▪ Vertex AI: Feature Store – for feature storing;
▪ Vertex AI: Explainable AI – for predictions understanding;
▪ Vertex AI: Model Registry – for model storing;
▪ Vertex AI: Pipeline – for system deploying.
🡺 Other Google Cloud Platform Tools:
First, we will start with a brief overview of creating a dataset.
To prepare metadata and images that are stored in Google Cloud Firestore and Google Cloud Storage, respectively, we used tools provided by libraries such as numpy, pandas, urllib, openCV. After the preprocessing of our dataset, we had the following pandas dataframe:
Here are the stages that we went through when building our recommendation CV system:
- Creating a custom dataset by performing all preprocessing operations using custom tools and libraries.
- Building and containerizing model training code in Vertex Workbench.
- Submitting a custom model training job to Vertex AI.
- Deploying the trained model to an endpoint, and using that endpoint to get predictions.
- Manipulating feature vectors to ensure image comparisons.
- Submitting the results to the store.
- Creating a pipeline that ensures the execution of all the steps above.
Below we present key information about the tools and technologies we used:
🡺 Dataset – Fashion Product Images Dataset [kaggle];
🡺 Pre- and post-processing of data – using custom ML tools and libraries;
🡺 Model – Custom Autoencoder model (Tensorflow, Keras);
🡺 Google Cloud Platform Tools for ML Development:
▪ Vertex AI: Workbench – for developing;
▪ Vertex AI: Feature Store – for feature storing;
▪ Vertex AI: Explainable AI – for predictions understanding;
▪ Vertex AI: Model Registry – for model storing;
▪ Vertex AI: Pipeline – for system deploying.
🡺 Other Google Cloud Platform Tools:
- Cloud Run, Compute Engine – computing;
- Cloud Storage, Firestore – storage;
- Cloud Build – multi-cloud;
- Secret Manager – identity and security;
- Cloud Composer (Airflow) – data and analytics;
- Artifact Registry – developer tools.
First, we will start with a brief overview of creating a dataset.
To prepare metadata and images that are stored in Google Cloud Firestore and Google Cloud Storage, respectively, we used tools provided by libraries such as numpy, pandas, urllib, openCV. After the preprocessing of our dataset, we had the following pandas dataframe:

Stages of creating the custom dataset: Importing metadata from Firestore

Stages of creating the custom dataset: dataframe of images and their metadata

Visualization examples of the prepared dataset
Then we split the data into training and test sets of images, normalized them and resized them to a uniform size.
Model
Once the research on various types of model architectures was conducted, we decided that the model structure, called ‘autoencoder’, is well suited for our task to find similar images.
What are ‘autoencoders’?
Autoencoders are direct propagation neural networks that reconstruct the input signal at the output. The aim of an autoencoder is to learn a lower-dimensional representation (encoding) for a higher-dimensional data, typically for dimensionality reduction, by training the network to capture the most important parts of the input image. Autoencoder models are commonly used for unsupervised learning tasks. They have been successfully applied in various domains such as computer vision, natural language processing, and recommender systems.
Let's look at the architecture of autoencoders:
1. Encoder: A module that compresses input data into an encoded representation.
2. Code: Being the most important part of the network, this module contains the compressed knowledge representations.. It's also often called an ‘encoded data’, ‘bottleneck’ or ‘embeddings’.
3. Decoder: A module that helps the network “decompress” the knowledge representations and reconstructs the data back from its encoded form. The output is then compared with a ground truth.
Model
Once the research on various types of model architectures was conducted, we decided that the model structure, called ‘autoencoder’, is well suited for our task to find similar images.
What are ‘autoencoders’?
Autoencoders are direct propagation neural networks that reconstruct the input signal at the output. The aim of an autoencoder is to learn a lower-dimensional representation (encoding) for a higher-dimensional data, typically for dimensionality reduction, by training the network to capture the most important parts of the input image. Autoencoder models are commonly used for unsupervised learning tasks. They have been successfully applied in various domains such as computer vision, natural language processing, and recommender systems.
Let's look at the architecture of autoencoders:
1. Encoder: A module that compresses input data into an encoded representation.
2. Code: Being the most important part of the network, this module contains the compressed knowledge representations.. It's also often called an ‘encoded data’, ‘bottleneck’ or ‘embeddings’.
3. Decoder: A module that helps the network “decompress” the knowledge representations and reconstructs the data back from its encoded form. The output is then compared with a ground truth.

There are various types of autoencoders, but among all of them we have chosen the "Convolutional Autoencoder" – a type of autoencoder specially designed for processing image data and using convolutional layers in encoder and decoder networks to collect spatial information.
We constructed our encoder and decoder networks with input and output layers. It was written using TensorFlow and Keras. You can see the structure below:
We constructed our encoder and decoder networks with input and output layers. It was written using TensorFlow and Keras. You can see the structure below:

Then we compiled the model ‘autoencoder’ with the ‘adamax’ optimizer and ‘mse’ as a loss:

***The 'adamax' optimizer is a variant of the Adam optimization algorithm, which is commonly used in deep learning and neural network training. Adam stands for "Adaptive Moment Estimation," and it combines the advantages of two other popular optimization methods: RMSprop (Root Mean Square Propagation) and Momentum.
***The MSE loss measures the average of the squared differences between the actual (observed) values and the predicted values produced by a model. It is used to assess how well a model is performing by quantifying the error or the difference between predicted and actual values.
Here we present the resumes for the autoencoder we built:
***The MSE loss measures the average of the squared differences between the actual (observed) values and the predicted values produced by a model. It is used to assess how well a model is performing by quantifying the error or the difference between predicted and actual values.
Here we present the resumes for the autoencoder we built:



Structure of our custom autoencoder
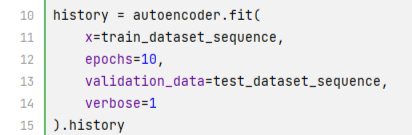
The next phase is dividing the entire dataset into training and test parts and passing them through the autoencoder network to train the model:
Storage
Google Cloud Vertex AI offers ready-to-use solutions for storing intermediate or final artifacts of the development process, such as model versions and function metadata. During this project, we got experience using Vertex AI: Feature Store and Vertex AI: Model Registry.
In the final development version, the main storage resources remain the same as in Part 1.1
Google Cloud Storage – for images, models, features.
Google Cloud Firestore – for all metadata - accompanying information about images in the store's catalog, selected sets of similar products, indicators and metrics of models.
Matching Similarities
This autoencoder model takes an input image and extracts its features. Then, the extracted features can be compared to the features of the other images to detect similarities.
After training the entire model, we took the encoder to perform further steps since we did not need decoded images.
The scheme below illustrates the usage of the encoder and extracted embeddings:
Google Cloud Vertex AI offers ready-to-use solutions for storing intermediate or final artifacts of the development process, such as model versions and function metadata. During this project, we got experience using Vertex AI: Feature Store and Vertex AI: Model Registry.
In the final development version, the main storage resources remain the same as in Part 1.1
Google Cloud Storage – for images, models, features.
Google Cloud Firestore – for all metadata - accompanying information about images in the store's catalog, selected sets of similar products, indicators and metrics of models.
Matching Similarities
This autoencoder model takes an input image and extracts its features. Then, the extracted features can be compared to the features of the other images to detect similarities.
After training the entire model, we took the encoder to perform further steps since we did not need decoded images.
The scheme below illustrates the usage of the encoder and extracted embeddings:

As a comparison tool we used the "NearestNeighbors(metric=”euclidean”)" offered by Scikit-learn.
***The Euclidean metric is a distance metric commonly used in machine learning and data analysis. It measures the straight-line distance between two points in a multi-dimensional space. In the context of Nearest Neighbors, the Euclidean metric is used to calculate the distance between data points in order to identify the nearest neighbors. The metric is named after the Greek mathematician Euclid, who is known for his work in geometry.
***The Euclidean metric is a distance metric commonly used in machine learning and data analysis. It measures the straight-line distance between two points in a multi-dimensional space. In the context of Nearest Neighbors, the Euclidean metric is used to calculate the distance between data points in order to identify the nearest neighbors. The metric is named after the Greek mathematician Euclid, who is known for his work in geometry.

Importing the NearestNeighbors(metric=”euclidean”) tool
Below is an example of the output data for the belt:

The found sets of similar images were uploaded to the Google Cloud Firestore and displayed in the online store interface in exactly the same way as in Part 1.1.:

Thus, unlike the previous stage, where we used GCP Vertex AI: AutoML tools and did not achieve the desired result, in a currentcase, using GCP Vertex AI: CustomML, we were able to build and deploy the ready-to-use recommendation-based visual search system:

The result of using the GCP Vertex AI: CustomML
Now let's have a look at the tables with metrics and results that are already familiar to you from the previous parts of the article.
Results
These are the key points of the technology stack that we used in this part:
Results
These are the key points of the technology stack that we used in this part:

The technology stack of building a recommendation system using Google Cloud Platform Vertex AI: CustomML
The main indicators that we have received at this stage using Vertex AI: CustomML:

Metrics of building a recommendation system using GCP Vertex AI: CustomML
*DISCLAIMER: These values are high-level evaluations. They are based only on our calculations and experience. The cost of using GCP tools should be calculated individually, based on a variety of factors, such as the model and capacity of the hardware etc. You can find the current version of the cost of Google components on the official website.
As you remember, in our previous step on GCP Vertex AI: AutoML we worked with only 800 images, spent $27.3, reached only the stage of receiving predictions lasted for 3 hours and we could not make the comparison.
In our current case we worked with the same 800 images, and the cost this time was $0.05 for a full cycle of the pipeline, which lasted for 45 minutes.
Obviously, this way of development using tools of Google Cloud Platform Vertex AI: CustomML looks more profitable within our goal in terms of time and material resources.
!NOTE: Be careful and always check the up-to-date information about the cost of using GCP tools in the official documentation to avoid the situation described in the following article: We Burnt $72K testing Firebase + Cloud Run and almost went Bankrupt [Part 1]
Now - our permanent rubric - pros, cons and pitfalls.
PROS of using Vertex AI: CustomML for Computer Vision tasks:
CONS of using Vertex AI: CustomML for Computer Vision tasks:
PITFALLS of using Vertex AI: CustomML for Computer Vision tasks:
In summary, Vertex AI: Custom ML for computer vision tasks offers many advantages, such as a simplified workflow and access to powerful infrastructure, but it is also associated with costs, complexity, and potential pitfalls related to data quality, model customization, and scalability.
As you remember, in our previous step on GCP Vertex AI: AutoML we worked with only 800 images, spent $27.3, reached only the stage of receiving predictions lasted for 3 hours and we could not make the comparison.
In our current case we worked with the same 800 images, and the cost this time was $0.05 for a full cycle of the pipeline, which lasted for 45 minutes.
Obviously, this way of development using tools of Google Cloud Platform Vertex AI: CustomML looks more profitable within our goal in terms of time and material resources.
!NOTE: Be careful and always check the up-to-date information about the cost of using GCP tools in the official documentation to avoid the situation described in the following article: We Burnt $72K testing Firebase + Cloud Run and almost went Bankrupt [Part 1]
Now - our permanent rubric - pros, cons and pitfalls.
PROS of using Vertex AI: CustomML for Computer Vision tasks:
- Simplified Workflow: Vertex AI offers a streamlined, end-to-end machine learning workflow for computer vision tasks, making it easier for developers and data scientists to build, train, and deploy models.
- Pre-built Models: It provides access to pre-built computer vision models, saving time and effort in model development. You can leverage these models as a starting point for your custom CV tasks.
- Scalability: Google Cloud's infrastructure allows easy scalability. You can train and deploy models with varying sizes and complexities to meet the demands of your application.
- AutoML Integration: Vertex AI integrates with AutoML, allowing automated model selection and hyperparameter tuning, which can improve model performance without manual intervention.
- Monitoring and Management: It provides tools for monitoring and managing deployed models, ensuring they perform well in production environments.
- High-Quality Data Labeling: Google offers Data Labeling Services, which can help to ensure high-quality labeled data for training computer vision models.
CONS of using Vertex AI: CustomML for Computer Vision tasks:
- Cost: Using Vertex AI can be expensive, especially if you need significant computational resources for training large models or if you have a high volume of inference requests in production.
- Complexity: Despite the simplified workflow, machine learning projects, especially in computer vision, can still be complex. Data preprocessing, feature engineering, and model tuning require expertise.
- Vendor Lock-In: By using Google Cloud's Vertex AI, you may become locked into their ecosystem, making it challenging to migrate to another cloud provider.
- Limited Customization: While pre-built models can save time, they may not perfectly align with your specific use case, requiring additional customization and fine-tuning.
PITFALLS of using Vertex AI: CustomML for Computer Vision tasks:
- Overfitting: Without proper regularization and validation techniques, your custom computer vision models might overfit to the training data, resulting in poor generalization to new data.
- Performance Expectations: Unrealistic performance expectations can lead to disappointment. Not all computer vision tasks can achieve human-level accuracy, and understanding the limitations of the technology is essential.
- Data Annotation Challenges: Annotating large datasets for training can be time-consuming and expensive. Ensuring the quality of annotations is crucial for model success.
- Pricing policy: Users who are not aware of the cost structure or have studied the vague pricing policy of using tools may inadvertently incur unforeseen expenses and may continue to use tools without thinking about the financial consequences. This may result in bills being significantly higher than expected. To avoid this, users should take the time to understand the cost structure of the tools they use.
In summary, Vertex AI: Custom ML for computer vision tasks offers many advantages, such as a simplified workflow and access to powerful infrastructure, but it is also associated with costs, complexity, and potential pitfalls related to data quality, model customization, and scalability.
Final Summary Comparison
Now let's summarize and compare the key points of all three methods of building a recommendation CV system that we have passed.

The main indicators that we received at all stages:

Visual comparison
How can we evaluate the accuracy and quality of models in addition to mathematical indicators, such as model loss or model accuracy?
We can examine their selection of identical products and compare them with each other.
Perhaps the method is controversial and can be time-consuming if we apply it to the entire dataset. However, this method is quite indicative within the small samples. Let's take a look at the results of our first and third generation models:






So, there are currently many tools and technologies for ML development, and at least two working ways to create a CV recommendation system from scratch to full deployment in the cloud that we have successfully tried: using only free user tools or using Google Cloud Platform Vertex AI technologies.
In our opinion, you can choose to:
🡺 Follow our first approach and use only free open-source tools if you don't want to go deeper in writing and tuning the model, and the quality of the result is not of paramount importance to you.
🡺 Opt for our second approach and automate ML development processes as much as possible, but only if you are sure that there is a ready-made solution from GCP Vertex AI: AutoML for your specific task, and you are ready to pay for it.
🡺 Consider our third approach and combine free custom and paid automated tools offered by GCP Vertex AI: CustomML to manage all development processes, to be confident in its quality, and not to worry too much about costs. However, one important note here - you should have enough time to navigate through some really challenging ML steps to build your system.
In any case, the choice is yours. We have simply introduced our experience in creating a recommendation system for visual search of similar images and shared our impressions of using advanced tools offered by Google Cloud Platform.
We hope this information will be useful. And we thank you for your attention and the time you spent reading this articles.