
The ChatGPT chatbot has caused a stir: users ask it questions and are surprised by the accuracy of the answers. Students are even using it to write graduate theses, and copywriters are publishing articles with titles like “Can ChatGPT replace copywriters?”
We decided to analyze the ChatGPT technology, examine the current state of open-source GPT-3-like models and answer the question: Can we train a GPT-3-like model at home?
For our experiment, we chose GPT-J and not the most powerful PC with an Nvidia GTX 1080TI graphics card (11 GB of VRAM). This proved to be enough not only to load the model, but also to fine-tune it. Keep reading to find out how we did it.
Why GPT-J?
GPT (Generative Pre-trained Transformer) is a giant neural network trained on a massive amount of data to predict the next word in the sequence. GPT models natural languages, remembers context and generates texts. If you want to learn more about GPT architecture, you can follow these links [1] and [15].
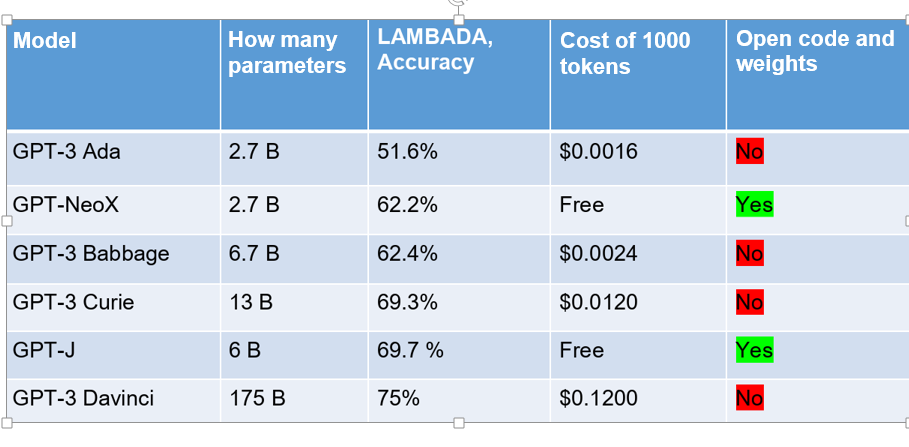
Let’s take a look at the table provided by the EleutherAI team to illustrate the advantages of their GPT-J model. We will provide only a portion of it, but you can view the full version by following this link: [2].
We decided to analyze the ChatGPT technology, examine the current state of open-source GPT-3-like models and answer the question: Can we train a GPT-3-like model at home?
For our experiment, we chose GPT-J and not the most powerful PC with an Nvidia GTX 1080TI graphics card (11 GB of VRAM). This proved to be enough not only to load the model, but also to fine-tune it. Keep reading to find out how we did it.
Why GPT-J?
GPT (Generative Pre-trained Transformer) is a giant neural network trained on a massive amount of data to predict the next word in the sequence. GPT models natural languages, remembers context and generates texts. If you want to learn more about GPT architecture, you can follow these links [1] and [15].
Let’s take a look at the table provided by the EleutherAI team to illustrate the advantages of their GPT-J model. We will provide only a portion of it, but you can view the full version by following this link: [2].

The benchmark values demonstrate how good the model is. Here are some benchmarks for GPT-J:
● LAMBADA is a dataset used to predict a word from a wide context. There are two metrics for this benchmark in the table: PPL – perplexity (less is better) and Acc – accuracy (higher is better);
● Winorgande is a dataset with text problems and answer options.
● Hellaswag is a commonsense challenge dataset.
● PIQA is also a commonsense benchmark that assesses the physical knowledge of the model.
According to the indicators, GPT-J is currently the highest-performing public model. Compared to OpenAI models, GPT-J shows comparable results with the Curie model, and is second only to the giant Davinci. The volume of the GPT-J training dataset is also impressive — 825 GB [4], and the number of parameters (weights) of the model is about 6 billion.
We chose Python, transformers, and Pytorch lightning as the main stack for GPT-J fine-tuning. GPT-J and other open-source community products can be found on the Hugging Face Hub [5].
8-bit GPT-J
EleutherAI’s model with float16 parameters requires about 21 GB of VRAM, which poses a problem for us. To allocate some capacity for this monster on our PC, we can use quantization [6, 7]. Quantization is a clever way to match the original float16 model parameters with int8 parameters and reduce the required memory by half. While we may lose some accuracy, the difference in accuracy between GPT-J and GPT-J-8bit, is within the margin of error [8], as per comparison between these models.
Thanks to the folks at Training Transformers Together [9], the quantized GPT-J [3] is available and requires only about 6 GB on GTX 1080 TI. Let’s say hello to it.
● LAMBADA is a dataset used to predict a word from a wide context. There are two metrics for this benchmark in the table: PPL – perplexity (less is better) and Acc – accuracy (higher is better);
● Winorgande is a dataset with text problems and answer options.
● Hellaswag is a commonsense challenge dataset.
● PIQA is also a commonsense benchmark that assesses the physical knowledge of the model.
According to the indicators, GPT-J is currently the highest-performing public model. Compared to OpenAI models, GPT-J shows comparable results with the Curie model, and is second only to the giant Davinci. The volume of the GPT-J training dataset is also impressive — 825 GB [4], and the number of parameters (weights) of the model is about 6 billion.
We chose Python, transformers, and Pytorch lightning as the main stack for GPT-J fine-tuning. GPT-J and other open-source community products can be found on the Hugging Face Hub [5].
8-bit GPT-J
EleutherAI’s model with float16 parameters requires about 21 GB of VRAM, which poses a problem for us. To allocate some capacity for this monster on our PC, we can use quantization [6, 7]. Quantization is a clever way to match the original float16 model parameters with int8 parameters and reduce the required memory by half. While we may lose some accuracy, the difference in accuracy between GPT-J and GPT-J-8bit, is within the margin of error [8], as per comparison between these models.
Thanks to the folks at Training Transformers Together [9], the quantized GPT-J [3] is available and requires only about 6 GB on GTX 1080 TI. Let’s say hello to it.

The first step is to determine what the model takes and returns, which refers to its input and output, respectively, as well as its dimensionality. Specifically, the model takes a sequence of words and returns the next word probabilities for the next word in the sequence. GPT is a highly attentive listener, as it immediately attempts to predict the next word once it has “heard” the current one.
Input
This is what the input data looks like:
Input
This is what the input data looks like:

The model takes a vector of tokens (input_ids) and the attention mask. Both elements have a maximum length of 2048.
● The token vector consists of integers: IDs of tokens from the model dictionary. The model dictionary contains 50,257 tokens;
● Attention mask: a vector with zeros and ones, whose task is to tell the model which tokens to pay attention to (1) and which not (0).
In order to effectively communicate with GPT, we need to use words that are already in its vocabulary and prioritize the important ones for the conversation. For example, there are several cases where we use 0 in the attention mask. Firstly, we use 0 for padding tokens when assembling the samples into a batch during the training phase, and we need to add padding so that the sample lengths match. Secondly, we can force the model to ignore certain tokens in the sample (e.g., the ones we want to predict) during training.
In the figure above, you can see how sample text turns into input_ids and attention_mask.
Output
The attentive GPT is constantly trying to predict the next word, but apart from attentiveness we can also count on its good memory. By default, the model returns the probabilities for the next tokens (logits) and the internal memory of the model (past_key_values). This is what the output of our model looks like:
● The token vector consists of integers: IDs of tokens from the model dictionary. The model dictionary contains 50,257 tokens;
● Attention mask: a vector with zeros and ones, whose task is to tell the model which tokens to pay attention to (1) and which not (0).
In order to effectively communicate with GPT, we need to use words that are already in its vocabulary and prioritize the important ones for the conversation. For example, there are several cases where we use 0 in the attention mask. Firstly, we use 0 for padding tokens when assembling the samples into a batch during the training phase, and we need to add padding so that the sample lengths match. Secondly, we can force the model to ignore certain tokens in the sample (e.g., the ones we want to predict) during training.
In the figure above, you can see how sample text turns into input_ids and attention_mask.
Output
The attentive GPT is constantly trying to predict the next word, but apart from attentiveness we can also count on its good memory. By default, the model returns the probabilities for the next tokens (logits) and the internal memory of the model (past_key_values). This is what the output of our model looks like:

Size of the logits tensor — (batch_size, sample_len, vocab_size). Our original sample ‘Hello, GPT-J! How are you?’ contains 12 tokens, so the logits have the form (1, 12, 50400).
For each token in the original sample, we obtain the probabilities for all tokens in the model dictionary. However, when generating our text, we are only interested in the probability of the last token. All or only selected probabilities for the input sequence can participate in the model's fine-tuning.
● past_key_value is the memory of our model. Tensor size: (n_layers, key_value, batch, n_attention_heads, sample_len, head_embedding_dimension);
● n_layers is the number of GPT-J layers;
● key_value is a tuple of keys and values in the context of the attention mechanism [10];
● batch is the batch size;
● n_attention_heads is the number of attention heads;
● sample_len is the sample length;
● head_embedding_dimension is the internal size of the attention head;
● n_layers, key_value, n_attention_heads, head_embedding_dimension are the dimensions relating to the model configuration.
Test task
Suppose we want to teach GPT to moderate chats, where the model will classify messages into three categories: hate, offensive, neutral.
To achieve this, we will use Hate Speech and Offensive Language Dataset [11]. Since GPT already knows a lot about language and words, we will reduce the amount of training data and randomly select only 1,000 examples. Before training, we will balance the classes beforehand and l choose 200 balanced examples for validation. We intend to train GPT-J-8bit to correctly generate the appropriate class label.
How do we prepare the data?
To teach GPT something, we need to provide it with a starting, and then evaluate its version of the phrase completion. Therefore, our training data consists of two parts: the seed and the completion.
Preparing the input sample plays an important role in model training. In addition to the text itself, which should be classified, you can also add additional information to the training sample: from special separators of sample blocks to entire instructions. One important aspect includes the special tokens that separate the seed from the completion (i.e., from the purpose of our model training). By using these separator tokens, we specify when we expect our GPT to do what we want.
For each token in the original sample, we obtain the probabilities for all tokens in the model dictionary. However, when generating our text, we are only interested in the probability of the last token. All or only selected probabilities for the input sequence can participate in the model's fine-tuning.
● past_key_value is the memory of our model. Tensor size: (n_layers, key_value, batch, n_attention_heads, sample_len, head_embedding_dimension);
● n_layers is the number of GPT-J layers;
● key_value is a tuple of keys and values in the context of the attention mechanism [10];
● batch is the batch size;
● n_attention_heads is the number of attention heads;
● sample_len is the sample length;
● head_embedding_dimension is the internal size of the attention head;
● n_layers, key_value, n_attention_heads, head_embedding_dimension are the dimensions relating to the model configuration.
Test task
Suppose we want to teach GPT to moderate chats, where the model will classify messages into three categories: hate, offensive, neutral.
To achieve this, we will use Hate Speech and Offensive Language Dataset [11]. Since GPT already knows a lot about language and words, we will reduce the amount of training data and randomly select only 1,000 examples. Before training, we will balance the classes beforehand and l choose 200 balanced examples for validation. We intend to train GPT-J-8bit to correctly generate the appropriate class label.
How do we prepare the data?
To teach GPT something, we need to provide it with a starting, and then evaluate its version of the phrase completion. Therefore, our training data consists of two parts: the seed and the completion.
Preparing the input sample plays an important role in model training. In addition to the text itself, which should be classified, you can also add additional information to the training sample: from special separators of sample blocks to entire instructions. One important aspect includes the special tokens that separate the seed from the completion (i.e., from the purpose of our model training). By using these separator tokens, we specify when we expect our GPT to do what we want.

We have achieved equally good accuracy using both seeds and instructions, as well as using seeds consisting only of the target text with a separator.
The only disadvantage of using the instructions is that the input samples are longer. However, instructions help the model to better understand what is required of it: GPT reads the instruction and, relating it to the result, it understands that all the answers are listed in the instruction, and it only needs to pick the right one. This enables GPT to solve other types of problems that can be formulated within the same instruction structure.
What to train? (Low-Rank Adapters)
In GPT-J-8bit, parameters are quantized. The training of quantized integer parameters using the usual algorithms does not seem to be a reasonable approach, not least because the range of values of the cross entropy loss function lies in [0, 1]. But even quantization does not save us from training a huge number of parameters and computational costs.
The authors of the article LoRA: Low-Rank Adaption of Large Language Models [12] came up with a very interesting and effective way to fine-tune huge models. Instead of training all the model parameters, they suggest freezing all the layers and adding a low-dimensional training adapter to each one. The adapter consists of two linear layers A and B, with sizes (d, r) and (r, d). Instead of training the “native” model W layer with a size of (d,d) (and d is equal to 4096 in GPT-J), it is proposed to train two smaller matrices. LoRA authors demonstrate that the optimal r is 2, which justifies the name of their approach — Low-Rank Adaption. Its logic is shown in the diagram:
The only disadvantage of using the instructions is that the input samples are longer. However, instructions help the model to better understand what is required of it: GPT reads the instruction and, relating it to the result, it understands that all the answers are listed in the instruction, and it only needs to pick the right one. This enables GPT to solve other types of problems that can be formulated within the same instruction structure.
What to train? (Low-Rank Adapters)
In GPT-J-8bit, parameters are quantized. The training of quantized integer parameters using the usual algorithms does not seem to be a reasonable approach, not least because the range of values of the cross entropy loss function lies in [0, 1]. But even quantization does not save us from training a huge number of parameters and computational costs.
The authors of the article LoRA: Low-Rank Adaption of Large Language Models [12] came up with a very interesting and effective way to fine-tune huge models. Instead of training all the model parameters, they suggest freezing all the layers and adding a low-dimensional training adapter to each one. The adapter consists of two linear layers A and B, with sizes (d, r) and (r, d). Instead of training the “native” model W layer with a size of (d,d) (and d is equal to 4096 in GPT-J), it is proposed to train two smaller matrices. LoRA authors demonstrate that the optimal r is 2, which justifies the name of their approach — Low-Rank Adaption. Its logic is shown in the diagram:

How to train? (Adam8bit)
To load a model into the graphics card RAM does not mean to tame it. Another graphics card is needed to fine-tune GPT using standard techniques, but we will do without it, and use the quantized optimizer.
The standard tool for training model parameters is the Adam optimizer. But we will need an efficient analogue. Authors of the 8-Bit Optimizers via Block-wise Quantization [13] article propose to quantize the optimizer, in particular its states that, include statistics on gradients (corrections) for model parameters. Moreover, block-wise quantization is proposed, which can be performed in parallel. The figure from the original article illustrates the point perfectly:
To load a model into the graphics card RAM does not mean to tame it. Another graphics card is needed to fine-tune GPT using standard techniques, but we will do without it, and use the quantized optimizer.
The standard tool for training model parameters is the Adam optimizer. But we will need an efficient analogue. Authors of the 8-Bit Optimizers via Block-wise Quantization [13] article propose to quantize the optimizer, in particular its states that, include statistics on gradients (corrections) for model parameters. Moreover, block-wise quantization is proposed, which can be performed in parallel. The figure from the original article illustrates the point perfectly:

Thanks to the authors for also publishing the bits and bytes [14]repository with an implementation of their approach.
Final preparations and training
We have outlined the key steps required to refine our use of GPT-J. However, to train GPT-J to perform the exact tasks we want, we need to somehow point out its errors. We use the loss mask in our code to take only what should be generated from the model predictions and make the error propagate backwards only over these tokens. This way, we will not calculate the error in the seed, but only in the continuation (loss). And the model will better understand what we want from it. In addition, if we are solving a classification problem, we can calculate the accuracy of the predictions. This will be the metric for the model's performance.
This is what the model training step looks like:
Final preparations and training
We have outlined the key steps required to refine our use of GPT-J. However, to train GPT-J to perform the exact tasks we want, we need to somehow point out its errors. We use the loss mask in our code to take only what should be generated from the model predictions and make the error propagate backwards only over these tokens. This way, we will not calculate the error in the seed, but only in the continuation (loss). And the model will better understand what we want from it. In addition, if we are solving a classification problem, we can calculate the accuracy of the predictions. This will be the metric for the model's performance.
This is what the model training step looks like:

We can use batches depending on the length of the samples and the memory capacity of the graphics card. We need to make all the samples the same length by padding the short samples and trimming the long ones. Batching will help speed up the training process.
Once the GPT-J architecture with adapters is assembled, the training data is loaded and preprocessed, and the Adam8bit optimizer is also ready. We can start fine-tuning and validation.
We will train the model over three epochs and also compare the four approaches:
● Training 1D model parameters (those layers where using an adapter makes no sense) — 861 K of training parameters;
● Adapters only for attention layers — 2.7 M of training parameters;
● Adapters for all layers — 5.2 M of training parameters;
● Few-shot — no training.
Since we are dealing with a highly sophisticated language model, that knows a lot about language, so we can do without training data altogether and rely on the model itself. The Few-shot approach, described in an article by the OpenAI team [15], suggests using several training samples in the seed, resulting in completions for new cases.
Outcomes
First, let’s look at the report [16] on our GPT-J training. We need a graph with the loss parameter to ensure the model is learning and loss decreases over time from epoch to epoch. And we expect the accuracy to grow.
Once the GPT-J architecture with adapters is assembled, the training data is loaded and preprocessed, and the Adam8bit optimizer is also ready. We can start fine-tuning and validation.
We will train the model over three epochs and also compare the four approaches:
● Training 1D model parameters (those layers where using an adapter makes no sense) — 861 K of training parameters;
● Adapters only for attention layers — 2.7 M of training parameters;
● Adapters for all layers — 5.2 M of training parameters;
● Few-shot — no training.
Since we are dealing with a highly sophisticated language model, that knows a lot about language, so we can do without training data altogether and rely on the model itself. The Few-shot approach, described in an article by the OpenAI team [15], suggests using several training samples in the seed, resulting in completions for new cases.
Outcomes
First, let’s look at the report [16] on our GPT-J training. We need a graph with the loss parameter to ensure the model is learning and loss decreases over time from epoch to epoch. And we expect the accuracy to grow.

Now, let’s test the OpenAI models through the API under identical conditions. Here’s the report on fine-tuning GPT-3 Ada and GPT-3 Davinci [17]. The loss value may differ a lot from our model because of the difference in loss functions. We used the standard cross entropy in our approach.

Let’s take a look at the table of prediction accuracy of all tested models and approaches:

We’ve achieved better accuracy than OpenAI models for the test moderation task under identical conditions. Adapters ensure the best accuracy, and the more of them we use, the more accurate model predictions we have. The Few-shot approach leaves much to be desired. And ChatGPT (GPT-3.5-turbo) gives very mediocre accuracy, although better than GPT-J without fine-tuning.
We’ve trained GPT-J at home, and it is not inferior to the development results of large companies. It is important to note, however, if you fine-tune the OpenAI GPT-3 model as the API documentation suggests (without instructions, just raw text with a separator), then Davinci shows identical accuracy of 84%. On the other hand, you have to pay for the use of fine-tuned OpenAI models: for example, to generate about two printed pages of text by the coolest model, we will pay 12 cents, and the cost includes seeds.
We’ve trained GPT-J at home, and it is not inferior to the development results of large companies. It is important to note, however, if you fine-tune the OpenAI GPT-3 model as the API documentation suggests (without instructions, just raw text with a separator), then Davinci shows identical accuracy of 84%. On the other hand, you have to pay for the use of fine-tuned OpenAI models: for example, to generate about two printed pages of text by the coolest model, we will pay 12 cents, and the cost includes seeds.
Advantages of instructions in seeds
We conducted another experiment to confirm that adding instructions to seeds does have advantages. We asked the model to choose a category for the news headlines from the BBC website.
The fine-tuned model shows that, thanks to the instructions in the seeds, it has learned to understand what we want it to do without additional training on the new categories.
We conducted another experiment to confirm that adding instructions to seeds does have advantages. We asked the model to choose a category for the news headlines from the BBC website.
The fine-tuned model shows that, thanks to the instructions in the seeds, it has learned to understand what we want it to do without additional training on the new categories.

- Building a GPT-like Model from Scratch with Detailed Theory and Code Implementation / Хабр (habr.com)
- EleutherAI/gpt-j-6B · Hugging Face
- hivemind/gpt-j-6B-8bit · Hugging Face
- The Pile (eleuther.ai)
- Models - Hugging Face
- How to accelerate and compress neural networks with quantization | by Tivadar Danka | Towards Data Science
- Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware Training with NVIDIA TensorRT | NVIDIA Technical Blog
- Jupyter Notebook Viewer (nbviewer.org)
- https://training-transformers-together.github.io
- [1706.03762] Attention Is All You Need (arxiv.org)
- Hate Speech and Offensive Language Dataset | Kaggle
- [2106.09685] LoRA: Low-Rank Adaptation of Large Language Models (arxiv.org)
- [2110.02861] 8-bit Optimizers via Block-wise Quantization (arxiv.org)
- TimDettmers/bitsandbytes: 8-bit CUDA functions for PyTorch (github.com)
- [2005.14165] Language Models are Few-Shot Learners (arxiv.org)
- https://api.wandb.ai/links/vetka925/d7bb74kg
- https://api.wandb.ai/links/vetka925/krtz93ul
- vetka925/gpt-j-8bit-lightning-finetune (github.com)